By clicking “Accept”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. View our Privacy Policy for more information.
A deep dive into common Git techniques our Product Engineers use at Risk Ledger.
Bruno Calogero
|
Engineering
September 16, 2021
12
mins read
Share
Using git can be daunting at first. Like my good friend Chris once said, "everyone knows the happy path but the minute it gets hairy we're all screwed".
I've decided to take a closer look at what git commands our engineering team uses on a day to day to get out of hairy situations.
This first part will dive and revisit some of the basic git commands and will serve as a basis for the second part which will look into some of our favourite git tricks, workflows, case studies & more advanced scenarios we sometimes get into.
We will be using a Github repository that I have created and can be foundhere.
I actually messed up multiple times doing this, goes to show, git fixes become an intuitive thing after a while.
Our git branching & versioning tree
Before we dive into any commands, we need to understand the versioning tree of our project.
Our versioning tree consists of
A master branch containing all our production-ready code. This branch has a protection rule that requires opening a pull request (PR) before merging onto it.
A dev branch containing code that is bundled and released periodically to the master branch. We like to use dev as our staging environment.
Feature branches. These are branched off of dev and contain logic and commits specific to a task or feature that is being developed.
We like to keep our commit history clean on our dev and master branches.
We therefore squash and merge our feature branches onto dev when a PR is opened and merged. Regardless of how many commits a feature branch has, once it is merged, all the commits are squashed into a single commit, that usually has the title of the PR. We then periodically merge code to master from dev via releases.
Visualising our git tree
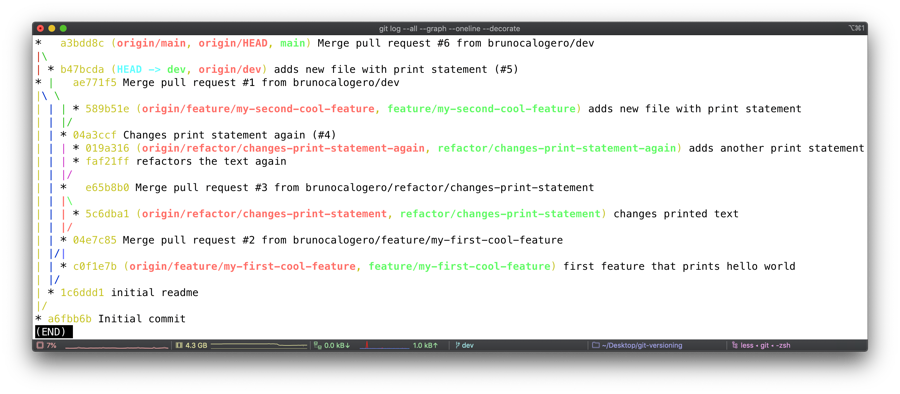
Visualising the versioning tree can be extremely powerful, there are several ways to do this but a favourite is the memorable "A DOG" git log command.
git log --all --decorate --oneline --graph
This command is used to get an overarching view of what is going on in the project in the form of a graph.
You can compare branches visually, you might be interested in specific commits from other branches for more complex operations (some of which we will visit later...).
This command is especially important if you are working with feature branches in your project. The standard git log will show you a flat commit history and it's hard to see what commit is part of what branch unless explicitly specified.
Many create bash aliases to avoid typing the whole thing, this sort of "macro-ing" also greatly improves productivity. You can even pass parameters to aliases!
When typing the above, the version tree gets printed out as below. The project has been pre-prepared with a bunch of commits, feature branches that were merged into dev and releases that were merged from dev to master . This was done to make it look as much as possible to our codebase.
It can look like a lot of information but we can easily decompose this and read it line by line from the bottom of the tree to the top of the tree.
Indeed, multiple things are displayed: commits, branches, PR commits (that were merged OR squash merged) and release commits (merged).
We can also see where the 'remote' or 'origin' (red) branches are vs the 'local' version of those branches are (green) - I'm referring to the names here not the tree. More info on this in the next section.
I suggest reading this and the above image side by side, all PRs availablehereand referenced with PR #
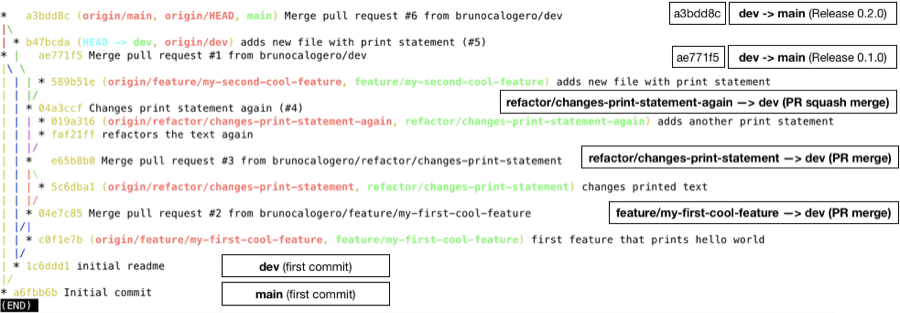
Taking a closer look and labelling where branches were merged, we get a better idea of what is going on at a high level:
We start off with a master branch & we branch off the latter to create a new dev branch with commit 1c6ddd1 .
We make our first release by opening and merging a release PR (#1)from dev to master forming commit ae771f5 (Top tip: the printing of the tree isn't always perfect so look at the '*' sign instead of the alignment).
We then make a series of feature branches, by branching directly off of dev.
The first two are merged "normally" (#2 & #3) & the subsequent two are squash merged (#4 & #5). This was mainly done for the sake of demonstrating what the tree would look like, but as mentioned above, all of our feature branches are squash merged.
A final release (a3bdd8c) is then made back into master, with all the changes merged & "squash merged" into dev.
There are more advanced ways to use this command.
You can add dates to the commits, authors and many more colorful things, but at the end of the day ADOG is easy to memorise and gets you going fast.
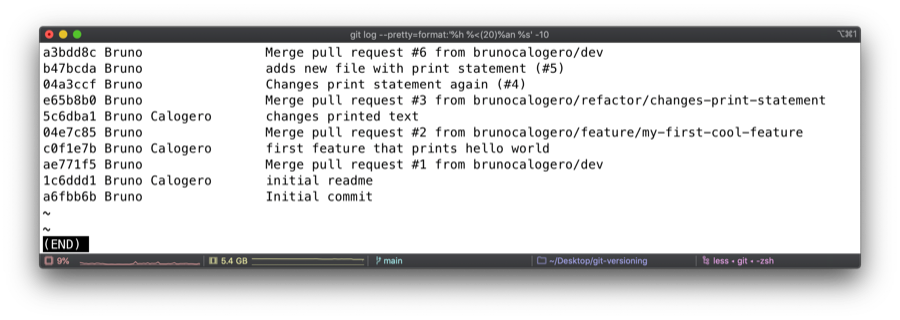
Using the standard git log command is also powerful but you won't be able to distinguish which commit is part of which branch. In my experience, this is mainly used to figure out the hash of a recent commit for future more complex operations.
git log --pretty=format:'%h %<(20)%an %s' -10
Taking a look at the commits associated with merging feature branches into dev: notice how you cannot see the commits of a branch that has been "squash merged" (04a3ccf & b47bcda), unlike when simply merging (04e7c85 & e65b8b0). In other words, if we had squash merged our first feature branch for example, we wouldn't have seen commit c0f1e7b.
Working on branches
Most of the git commands that we use daily revolve around branches. Changes that are staged, committed and pushed onto a branch can be manipulated as one wishes, however it can easily get messy.
Some semantics are needed for us to understand the basics of a branch:
origin : this is a remote repository that a project was originally cloned from. It's often simply referred to as 'remote'.
HEAD: When you see this in the versioning tree, it refers to the current branch you are on locally (e.g when you git checkout a specific branch, or when creating a new branch locally with a -b flag).
NOTE: a 'detached HEAD' when developing locally can be something common, especially when rebasing.
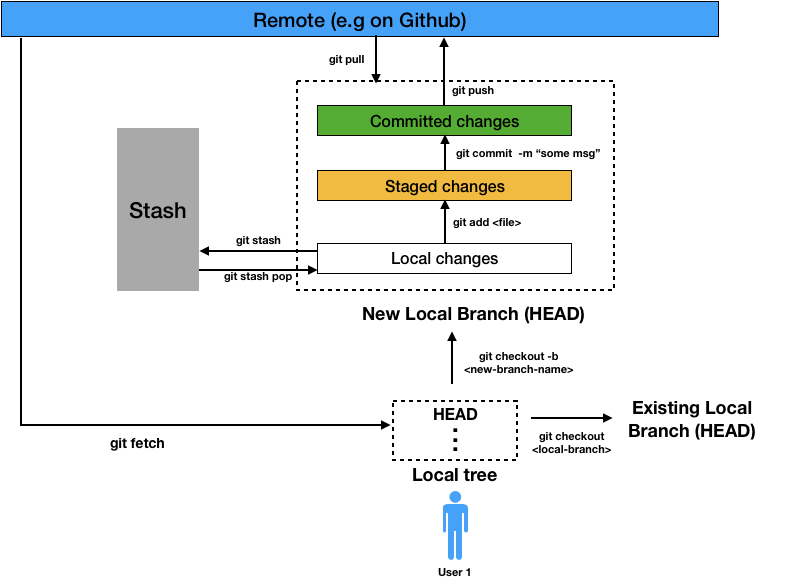
It's very helpful to visualise things here so as to not get confused with the myriad of commands I'm about to throw your way, so I came up with this classic diagram. Please use it as a reference to help you understand what in the world is going on.
The most basic commands used include:
git status
git branch
git checkout (-b) <branch-name>
This allows you to checkout an existing branch or create a new local branch (-b) based on where your HEAD currently is.
If you are simply checking out a remote branch, make sure you run a quick git fetch so all your local tree refs are up to date with what is on remote. It's always good for you local tree to be up to date with what is on "remote", you're essentially staying up to sync.
git add (-p) <file>
This "stages" your local changes.
To be honest I often use my text editor (vscode) for this. If not I usually just stage everything with git add . . It might well be that you don't want to stage a whole file but just part of it, in this case you would use the patch -p flag (more info here). This can get messy so make sure you get familiar with your text editor of choice to make this simpler.
git commit -m "some commit message" (--no-verify)
This "commits" your staged changes, in other words signs and bundles them with a message into a stack of commits which can then be pushed to remote.
You can set up your repo to use git "hooks". We use the --no-verify flag when commiting if we want to skip our commit "hooks", which includes whatever you wish to do as your staged files are commited. One of our hooks for example does not allow us to commit if the staged file changes include linting errors.
git push (—force-with-lease)
This pushes our commit stack to the remote version of the branch.
If the local branch doesn't exist yet on "remote" you will be prompted to "up-stream" it when pushing (git push --set-upstream origin)
In some cases we "force" our changes onto remote, this often happens when rebasing.
git branch -D <branch-name>
This deletes a local branch. We usually do this when we don't need a local branch anymore.
Most used basic commands
git blame
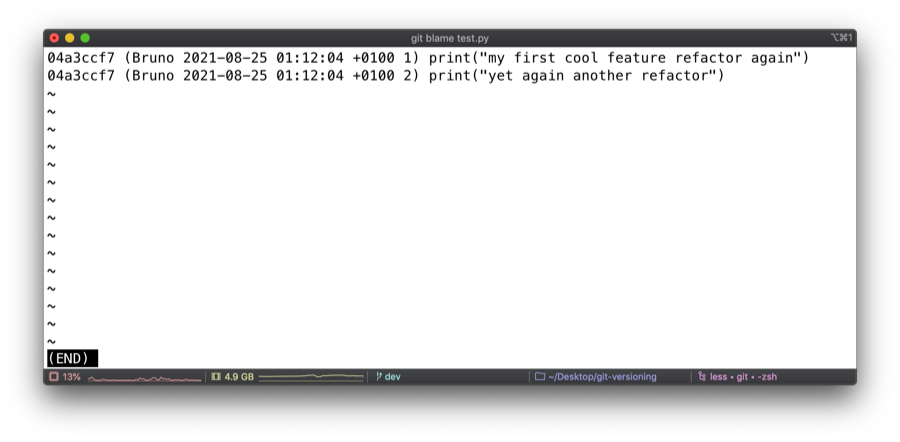
git blame is used to blame your co-workers (I joke). It basically "annotates each line in the given file with information from the revision which last modified the line". This comes out of the box with most editors. It can be useful to figure out the commit hash responsible for changes in a file.
With this, we can also add the importance of naming PRs correctly and concisely. As mentioned before, the latter are "squashed and merged" into dev, meaning all the commits of the branch are squashed into a single commit and merged into dev. This commit usually ends up being the title of the PR.
Commit 04a3ccf7 corresponds to "Changes print statement again".. from PR #4 which holds the same name as the commit.
git stash
git stash has to be my all time favourite command and one of the most powerful tools at your disposal.
The stash is essentially a stack. You can push in local changes that you don't need at the moment and might want to save for later. You can then get ahold of them again anywhere by simply popping the last stash (LIFO) using git stash pop .
As of git 2.11 one can select a specific stash to be popped instead of just the latest stash using git stash apply n where n is the stash number.
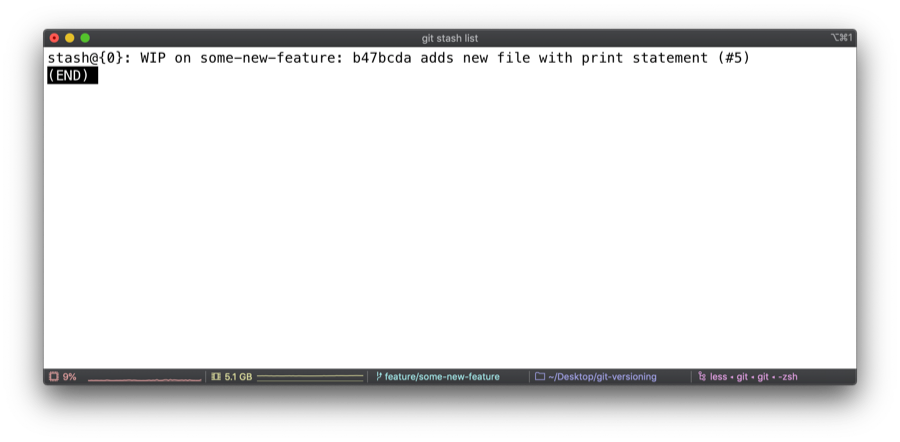
You can list the changes pushed onto the stack using git stash list and inspect them using git stash show.
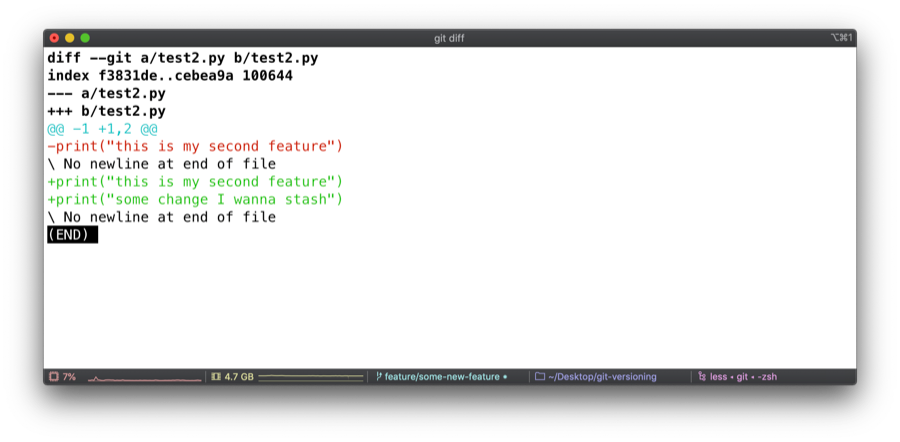
We add a line of code and demonstrate the git diff
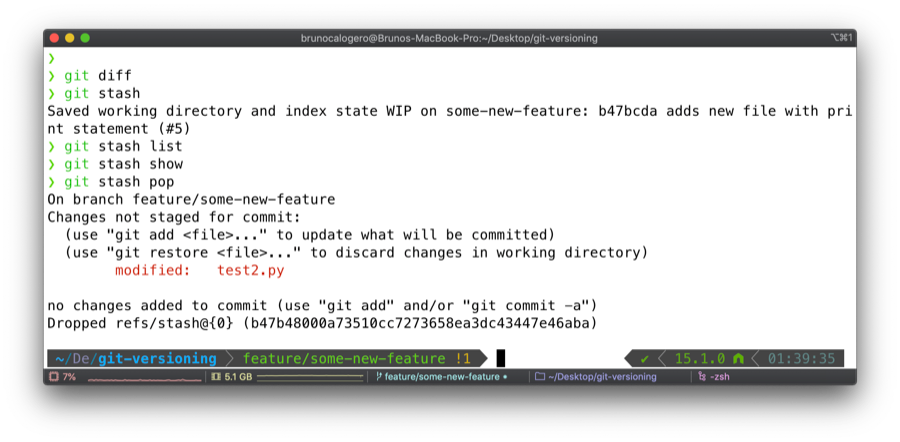
We git stash and git stash list , we can see a single element in our stash stack. We can resume changes as we please and switch branches if we like.
Finally we want our stashed changes back so we git stash pop
git rebase
git rebase is probably one of the most common commands used by us.
The most common use case is when we create a feature branch off of dev and in the mean time other feature branches are being merged into dev. Some of the files that we are currently changing might have been modified by the other feature branches that were merged. This can cause merge conflicts.
Another use case might be that we have a feature branch on top of another feature branch, we merge the first feature branch and now need to fix up the history of the second feature branch.
We resolve this by getting the latest version of dev locally (switch to the dev branch and run a git pull --rebase) going back onto our feature branch and running an interactive rebase: git rebase -i origin/dev , you then have the choice to drop or modify commits of your feature branch and progressively fix your merge conflicts.
To more safely rebase and be able to have another go at it (if some mistake was made), one can also create a temp branch on top of the feature branch being rebased. This can make it easier to compare any before & after too.
Fixing merge conflicts might require you to force push, I recommend always being safe and using the —force-with-lease
git reset
git reset can be your best friend at times. It allows you to undo changes that have been commited (and also potentially pushed).
The most common scenario for me is when I accidentally forget to add a change to a commit that i've already sent off. I also use this when I create WIP commits and I want to undo them so as to be able to take the changes from that "WIP" commit and actually create a clean commit history.
git reset --soft HEAD~1 or giving it a specific commit hash, allows you to get all the changes back into your working directory (local changes)
The --hard flag won't give you the file changes from the commit back into your working directory and will simply reset the commit as is.
"git reset --hard origin/my-branch can be used when checking out my-branch locally and some merge or pull or fetch or something has just gone wrong and I just want my local to be the same as the remote (after making sure of course that remote really does have everything I need and I won't be deleting something locally)" - Fred from Risk Ledger.
git cherry-pick
Honestly this article does an amazing job at explaining cherry picking so I won't start reinventing the wheel again.
This is useful when you need to selectively grab commit(s) from elsewhere and append them to your working HEAD.
Conclusion
Git is a powerful tool when the basics are mastered correctly.
We have visited some of the essential commands that we use here at Risk ledger and believe me when I tell you that they've saved us numerous times.
There are multiple case scenarios we will explore in the next part:
Having a large PR (too many changes for a single branch) and having to create a bunch of smaller ones from the latter.
Dealing with branches on top of other branches and fixing merge conflicts.
Creating a new branch with a selection of cherry picked commits from other branches.
At the end of the day, nothing beats the official git book, so if you haven't yet, do yourself a favour and check it out here.
Feel free to leave a follow on twitter if you liked the content!






.svg)