
July 15, 2026
・
5
mins read

Risk Ledger allows our customers to efficiently work with their suppliers towards documenting and improving their supply chain security. By working together, sharing data and pieces of evidence, the network can grow stronger and defend-as-one. This is a key part in ensuring the industry is moving in the right direction and minimising weak links. However, behind the scenes we need to ensure that this file sharing process is not used as a mechanism to attack and infect other companies.
When a supplier shares the security controls that they have put in place, we often require them to provide evidence in the form of documentation. This opens up a possible cross company attack vector where one company is able to upload an infected document, and another downloads it when reviewing their documentation. This is unacceptable, and our work on safe file uploads prevents this type of attack.
Simply checking file extensions and content type is not good enough.
Limiting the files which can and can't be uploaded is a good start. By eliminating executables you already prevent a large number of possible attacks. Common file types we would accept are word documents, spreadsheets, and images, however they still leave a lot of possible attack vectors, and using a list of permitted file types alone isn't sufficient.
This is called "MIME Type Spoofing", and it's fairly trivial to accomplish. Multipurpose Internet Mail Extensions (MIME) is only to be used as an indicator, and so while we can check for a file's MIME type, we should only ever really use this as guidance and not rely on it solely for security purposes.
The real validity check occurs as we scan a file using a virus scanner. Passing a file through a tool such as ClamAV is a great way to check the file against frequently updated virus definitions. By designing a centralized uploads service with ClamAV, we're able to verify that any and all files uploaded to our object storage are scanned before they are made available to users on our platform.
We made a conscious decision to prevent any users from downloading any files which have not yet been scanned. Given the end-to-end pipeline only takes a matter of seconds, most customers never realise the extent of validation and scanning which is taking place in the background. Any files which are found to be infected are also prevented from being downloaded and we are then able to take action and inform customers of a potential threat.
Making sure we are able to meet demand and scan files quickly as we continue to grow was an important design consideration. We also knew that in future, we’d like to add extra steps to the file processing pipeline - ranging from Optical Character Recognition to generating thumbnail images.
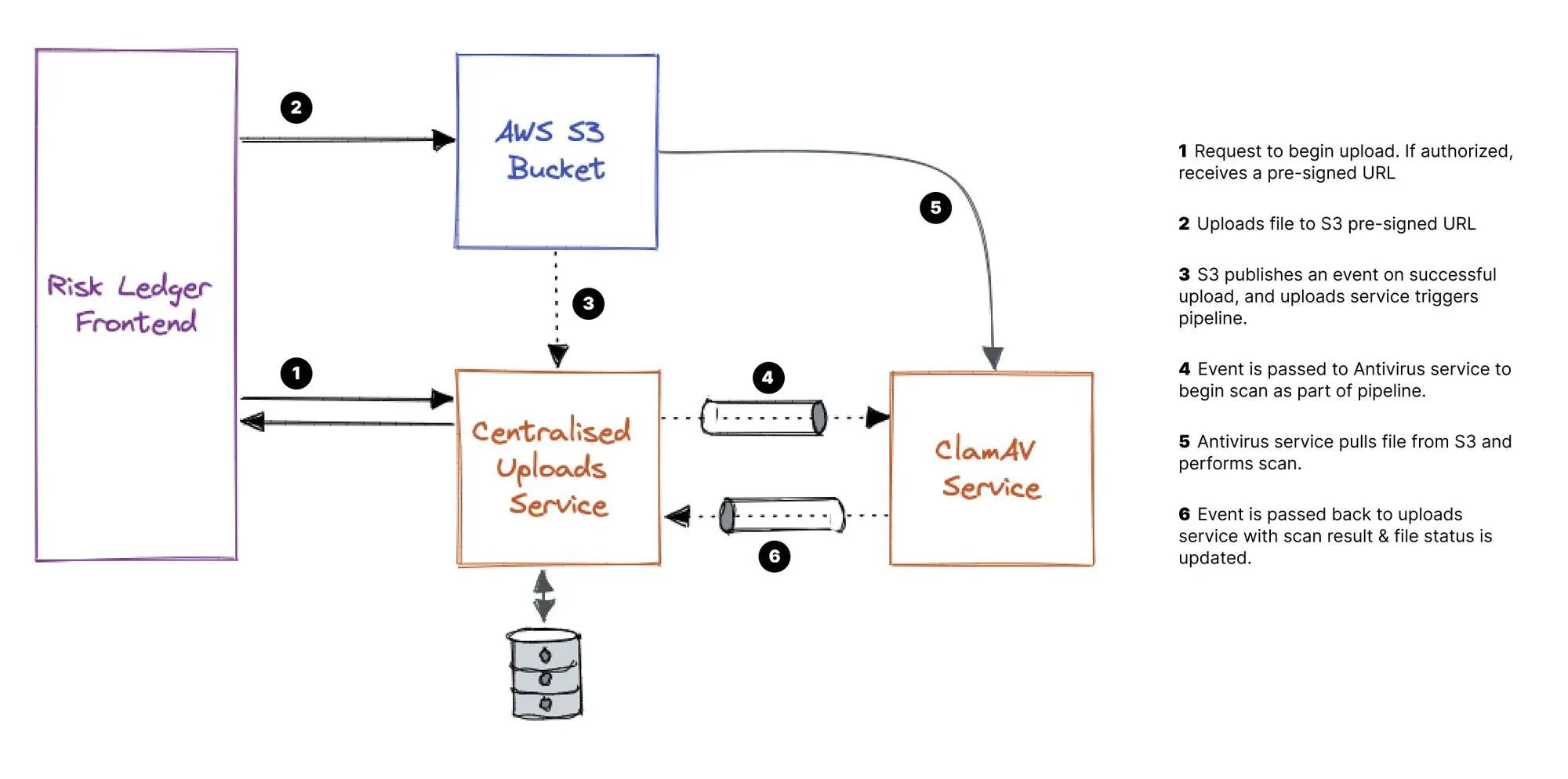
AWS S3 sits at the core of our file uploads solution, and we use presigned URLs to ensure only authenticated users can upload and download the files for which they are authorized.
But how do we process files between upload and download? We expanded on our existing event-based architecture in our approach to the problem, which allows services to subscribe to certain topics.
S3 fires an event which is consumed by our new centralised uploads service on the successful upload of a new file. Once we have made a record of the new file in the database, we kick off the processing pipeline by publishing another event, subscribed to by the antivirus service. The file is pulled from S3, scanned by ClamAV, the result of which is then itself published. The file status is then updated in our uploads service - which has the final say on whether a file can be accessed by our customers or not.
Using an event-based design offers us a lot of flexibility: we're able to rely on automated retries and dead letter queues if a scan attempt were to fail. Given the computational costs related to scanning a file, this design also means we can happily increase the number of antivirus instances at short notice.
A downside though is the time it takes for specific actions to complete and return to the client. We understand that in most instances the result will come back almost instantly, however one must consider that network connections drop, large files need to be transferred and scans may be slow. To resolve the issue of eventual consistency within the user interface, we currently make use of polling.
Here a trade-off was made: polling has its flaws, particularly if there are many “realtime” updates needed. But in this case, we only need to poll for updates to files that have not yet finished processing which should be a minimal number at any one time. Ultimately it offers a quick and seamless experience for our customers, without the overhead of implementing websockets or server-sent events, and we make use of exponential backoff such that we don't needlessly query the uploads service.
In the case that a file fails processing, we'll surface an error and prevent anyone from downloading the infected file.
As alluded to above, we have big plans to add further steps to our file processing pipeline in future. Can we generate preview images to show as thumbnails to our users? Could we automatically convert Word documents to a more friendly PDF format? How about automatically pulling out details and expiry dates from certificates? Or even identifying weaknesses within a company’s policy documents?
If these sound like the sorts of technical problems you would like to work on, Risk Ledger are hiring and you can find out more here.

Monthly research, case studies and practical guides you won't find anywhere else.
Join thousands of security managers turning their TPRM programmes into success stories.



.svg)